Monitoring avec Postgres
 2017-05-23
2017-05-23
 735 mots, 4 minutes de lecture
735 mots, 4 minutes de lecture
 Emeric Tabakhoff
Emeric Tabakhoff
 2017-05-23
735 mots, 4 minutes de lecture
Emeric Tabakhoff
2017-05-23
735 mots, 4 minutes de lecture
Emeric Tabakhoff
Voici un rapide retour sur la solution de Steve Simpson pour le monitoring d’infrastructures complexes donné le jour du PGDAY Paris, le 23 mars dernier. Les slides sont disponibles sur slideshare.
Le contexte : une infrastructure complexe avec de gros volumes de données et de charges (Multi-tenant massively parallel workload).
La problématique : comment monitorer tout cela ?
Deux réponses possibles
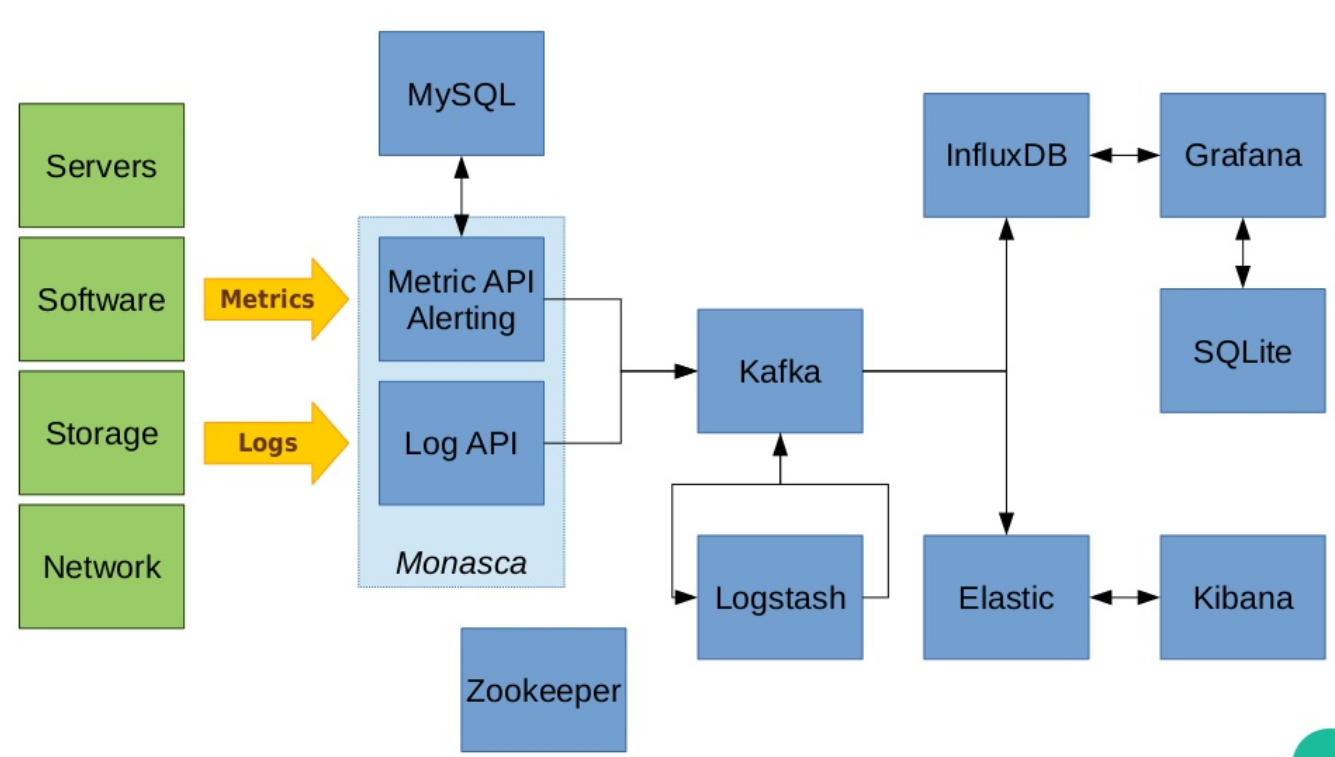
La première : ELK (Elastic Search - Logstash - Kibana) associé à InfluxDB + Grafana + SQLite avec en sus Kafka, MySQL et Zookeeper. Et tout cela fait beaucoup d’outils à mettre en place comme vous pouvez-le voir ci-dessous :
Ou alors… Simplement PostgreSQL ! (+Grafana)
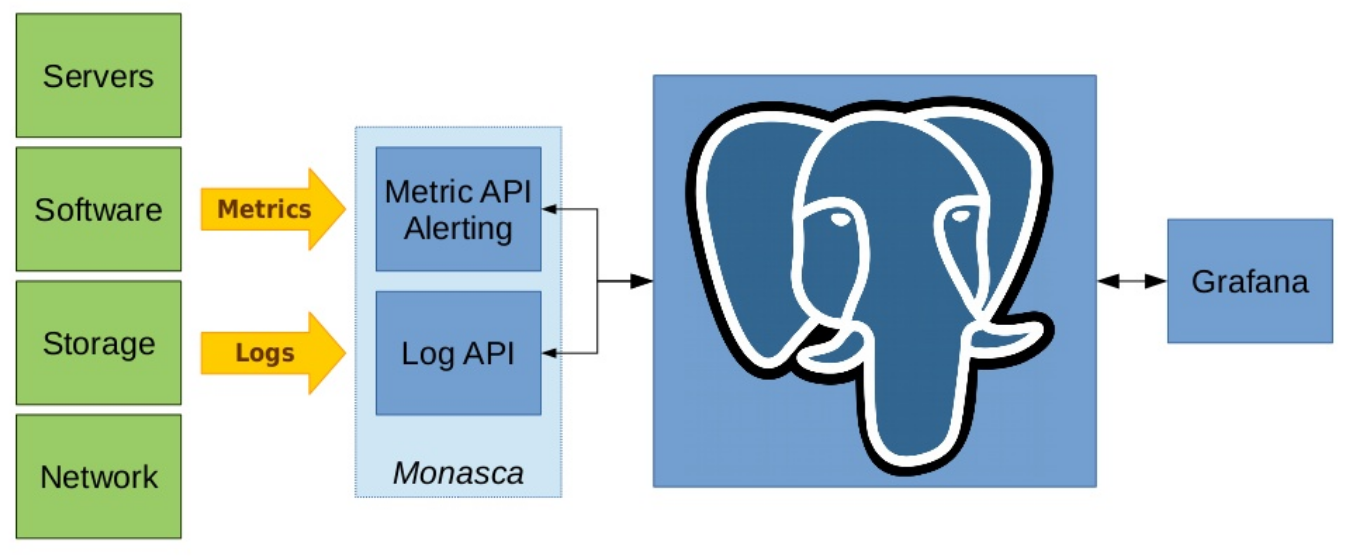
Steve commence par passer en revue les outils existants, avec leur entrée sur le marché. Les besoins sont listés un à un, les fonctionnalités employées une à une et ce, pour chacune des briques de l’infrastructure. L’intégralité des outils employés au départ est remplacée par PostgreSQL (et Grafana pour la partie graphique).
Il est en effet possible de faire absorber à PostgreSQL un gros volume d’information avec des structures de schema dénormalisées comportant des champs de type JSON et JSONB qui permettent une grande flexibilité de contenu.
Les différentes métriques sont stockées de cette façon ainsi que la liste des métriques elle même.
Les possibilités du language SQL dans PostgreSQL sont mises à contribution (fonctions TIME_ROUND, AVG, BETWEEN, @>…), de même que les index GIN (sur les champs JSONB).
Les fonctions utilisateur sont par la suite employées sur des parties de schéma normalisées pour diminuer la redondance des informations, organiser les données et les métriques brutes absorbées.
Pour grapher les données, une granularité minimale est nécessaire pour obtenir une représentation pertinente. Le filtrage/échantillonage et la renormalisation du schéma permettent de faciliter le requêtage et de diminuer la quantité de données en transit.
Pour les résumés (aggregats de données), ce sont encore les fonctions internes (TIME_ROUND, LEAST, GREATEST…) qui sont mises à profit ainsi que les triggers mais également les vues (jointures).
Ces résumés permettent d’obtenir un état général toutes les 5 minutes.
Ce jeu de données utilisé est donc faible et l’impact sur les performances est encore une fois limité par une utilisation judicieuse des points forts du SGBD.
La conférence est accompagnée de graphiques comparatifs de performance sur les temps de requêtages. L’orateur nous donne des exemples de requêtes, fonctions, triggers qui nous permettent de nous rendre compte de ce qu’il a fallu mettre en place en terme de language SQL.
Les insertions de données dans les différents régimes (dénormalisé, normalisé, résumé) sont comparées.
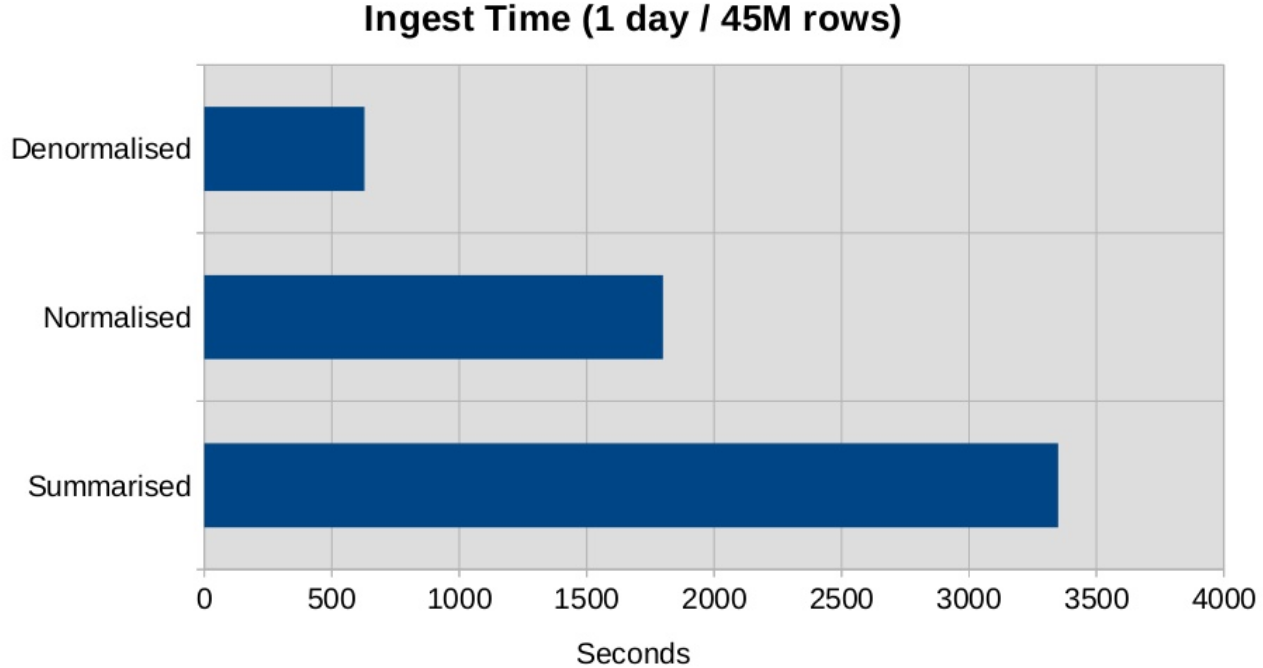
On s’aperçoit que les 600ms, 1750ms et 3300ms nécessaires pour absorber 45 millions de lignes (le monitoring d’une journée) sont des performances très intéressantes. Ce qui fait de PostgreSQL un sérieux challenger dans la liste des outils en compétition sur le marché des solutions de monitoring.
L’orateur nous propose les évolutions qu’il entrevoit pour son système. Notamment des résumés sur 30 minutes avec des requêtes plus larges. Du partitionnement par jour pour faciliter l’ingestion et la suppression régulière sur la durée. Un processing par lignes en batch avec des intervales. Et une ingestion asynchrone de l’ingestion des transactions.
Steve nous explique qu’il cherche à historiser sur 6 mois avec des espaces disques inférieur au Terabyte. Une autre contrainte imposée est de n’avoir que 100ms de requête.
Mais ça n’est pas tout, les autres fonctionnalités utilisées incluent la recherche dans les logs (type rsyslog) en stockage clé/valeur sur des champs JSONB (index GIN) avec FULL TEXT SEARCH (ts_query/ts_vector).
Pour finir, il utilise le parsing de log avec les REGEX contre une liste de patterns (stockés en tables pour plus de flexibilité). Les informations ainsi extraites sont insérées dans une table de logs avec un champ JSONB. Au vu des performances lors de l’ingestion de données pour les différents types de champs, Steve propose d’utiliser PostgreSQL pour le queuing également.
Tous les outils cités au début de la conférence sont finalement remplacés. Les informations brutes absorbées, puis ordonnées ne nécessite maintenant plus qu’une interface ergonomique pour être exploitées. Grafana est alors utilisé pour cette partie. Pour Steve, PostgreSQL est une boite à outils de données persistantes qui, de surcroit, utilise en natif du SQL.
Les utilisateurs de PostgreSQL ne cesseront jamais de m’étonner. Tant de flexibilité et de fonctionnalités !



LOXODATA
SÀRL au capital de 380 000 €
RCS Vesoul-Gray B 520 264 896
SIRET 520-264-896 00017
Code APE 6202A
N° TVA Intra Com. FR01520264896
Siège social: 31 rue Maurice Gillot, 70000 Navenne
Téléphone fixe: +33 1 797 2 5775
Directeur de la publication: Stéphane Schildknecht
Hébergeur :
OVH SAS
2 rue Kellermann
59100 Roubaix - France
RCS Lille Métropole 424 761 419 00045