Profilage de fonctions PL/PgSQL (partie 2)
 2017-04-05
2017-04-05
 936 mots, 5 minutes de lecture
936 mots, 5 minutes de lecture
 Sébastien Lardière
Sébastien Lardière
 2017-04-05
936 mots, 5 minutes de lecture
Sébastien Lardière
2017-04-05
936 mots, 5 minutes de lecture
Sébastien Lardière
Le langage PL/PgSQL est présent depuis près de 20 ans dans PostgreSQL.
Il ajoute des instructions procédurales au langage SQL. On peut ainsi écrire des procédures dans une base PostgreSQL.
Ses structures de contrôle sont très communes pour un développeur. Il intègre parfaitement bien le langage SQL, ce qui en fait un outil idéal lorsqu’un développeur veut implémenter ses algorithmes au plus proche des données.
Un premier article a montré l’installation et l’utilisation basique de ce profiler, ce second article se propose de montrer l’utilisation de l’outil dans le cadre de tests de charge, aussi appelés « benchmarks ».
Il n’est pas recommandé d’utiliser le profiler dans un système de production, en raison de la charge supplémentaire que le suivi du code apporte.
Le profiler est conçu pour être utilisé dans le cadre de tests de
charge avec, par exemple, pgbench ou tsung. Mais il peut aussi être utilisé pour
vérifier le bon fontionnement des procédures « maison ».
Pour illustrer cet article, nous avons choisi un simple script SQL qui insère des données dans une table partitionnée. Le partitionnement de données étant réalisé par des triggers écrits en PL/PgSQL, le profiler montrera le temps passé dans ces fonctions.
L’outil de partitionnement est disponible à l’adresse suivante : (https://github.com/slardiere/PartMgr)
La table partitionnée peut-être créée avec les commandes suivantes :
create schema partmgr;
create extension partmgr with schema partmgr;
drop schema if exists test cascade ;
create schema test ;
create table test.test1jour ( id int primary key,
ev_date timestamptz default now(), label int );
create sequence test.test1jour_id_seq ;
alter table test.test1jour alter column id
set default nextval('test.test1jour_id_seq');
create trigger update_row before update
on test.test1jour for each row
execute procedure partmgr.update_tuple();
create or replace function test.test_trigger ()
returns trigger
language plpgsql
as $BODY$
begin
if TG_OP = 'INSERT' then
raise notice 'Fct triggered on %', TG_OP ;
return new ;
elsif TG_OP = 'UPDATE' then
raise notice 'Fct triggered on %', TG_OP ;
return new ;
elsif TG_OP = 'DELETE' then
raise notice 'Fct triggered on %', TG_OP ;
return old ;
end if;
return null;
end;
$BODY$ ;
create trigger _insupdev before insert or update
on test.test1jour
for each row
execute procedure test.test_trigger () ;
insert into partmgr.part_table (schemaname, tablename, keycolumn,
pattern, cleanable, retention_period)
values ('test','test1jour','ev_date','D','t','2 month') ;
select partmgr.create_part_trigger('test','test1jour') ;
select * from partmgr.create ( (current_date - interval '2 month')::date,
(current_date + interval ' 2 month')::date ) ;
Le script testpart.sql est le suivant :
insert into test.test1jour ( ev_date, label ) values
( now() + interval '1d' * ((random() - 0.5) * 100)::int, 1);
Le script SQL est appelé par l’outil pgbench. En effet, au dela de
l’usage habituel, pgbench peut lancer n’importe quel script, avec de
nombreuses possibilités dépassant le cadre de cet article. Dans notre
cas, l’interêt est de lancer le test avec quelques clients (10)
pendant un temps donné (10sec), comme dans l’exemple suivant :
pgbench -c 10 -j 10 -T 10 -f testpart.sql
Le résultat du test de charge ne nous intéresse pas dans le cadre de cet article. Nous nous intéressons uniquement aux appels de procédures stockées.
Le module plprofiler doit être chargé dès le démarrage de l’instance
PostgreSQL, permettant le profilage global. Pour cela, il faut
modifier le fichier de configuration postgresql.conf :
shared_preload_libraries = 'plprofiler'
L’instance doit alors être redémarrée.
Lorsqu’un test de charge est en cours, il est alors possible de suivre
l’activité de toute l’instance PostgreSQL, en utilisant l’outil client
plprofiler :
plprofiler reset
plprofiler monitor --interval 10 --duration 300
La commande reset nettoie les données déjà collectées. La commande
monitor permet de collecter les données de profilage, ici pendant 300
secondes.
Les données de profilage peuvent alors être exportées pour être examiné dans un navigateur web :
plprofiler report --from-shared --output parttest01.html
Ce mode permet de ne pas modifier le test de charge, ce qui est particulièrement pertinent lors du test d’une application existante, ou il peut être difficile d’insérer les déclenchements du profilage.
L’extrait suivant montre la liste des fonctions, utilisée dans le test de charge, et donc identifiées par le profiler :

Puis, pour chaque fonction, le code est détaillé avec les informations associées aux lignes de code :
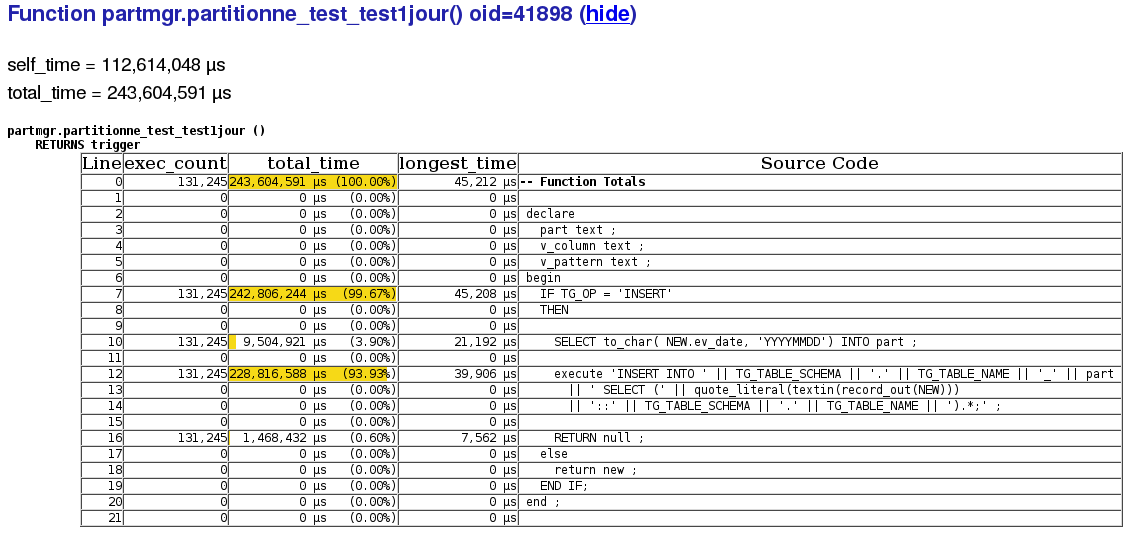
Lorsque le test de charge est “ouvert”, il est plus simple de déclencher le profilage aux endroits strictement nécessaires, afin d’obtenir des données pertinentes sur ce qui doit être testé.
Pour cela, il suffit d’activer le profilage à la demande, comme dans
l’exemple testpart.sql suivant :
SET plprofiler.enabled TO true;
SET plprofiler.collect_interval TO 10;
insert into test.test1jour ( ev_date, label )
values ( now() + interval '1d' *
((random() - 0.5) * 100)::int, 1);
Le simple lancement du test de charge déclenche alors la collecte des données de profilage :
pgbench -c 10 -j 10 -T 10 -f testpart.sql
Les données « partagées » du profiler peuvent être enregistrées dans une session, ce qui permet de cumuler plusieurs sessions, correspondant à des tests de charge distincts :
plprofiler save --name=parttest01
Enfin, il est possible de produire un rapport à partir d’une session enregistrée :
plprofiler report --name=parttest01 > parttest01.html
Au terme de ces 2 articles, on comprend que l’outil est d’une grande aide pour les développeurs qui cherchent à comprendre l’exécution dans le détail de leurs procédures stockées.
De même, l’administrateur de base de données confronté à des problèmes de performances y trouve un outil précieux, en complément de bien d’autres outils, pour identifier les points bloquants de l’instance.



LOXODATA
SÀRL au capital de 380 000 €
RCS Vesoul-Gray B 520 264 896
SIRET 520-264-896 00017
Code APE 6202A
N° TVA Intra Com. FR01520264896
Siège social: 31 rue Maurice Gillot, 70000 Navenne
Téléphone fixe: +33 1 797 2 5775
Directeur de la publication: Stéphane Schildknecht
Hébergeur :
OVH SAS
2 rue Kellermann
59100 Roubaix - France
RCS Lille Métropole 424 761 419 00045