Migration PostgreSQL (presque) sans arrêt de production
 2018-12-17
2018-12-17
 1727 mots, 9 minutes de lecture
1727 mots, 9 minutes de lecture
 Lætitia AVROT
Lætitia AVROT
 2018-12-17
1727 mots, 9 minutes de lecture
Lætitia AVROT
2018-12-17
1727 mots, 9 minutes de lecture
Lætitia AVROT
PostgreSQL 10 est sorti en octobre 2017, apportant de nombreuses nouvelles fonctionnalités dont la réplication logique, mais depuis, PostgreSQL 11 est sorti en octobre 2018 : il vous faut à nouveau migrer ! Dans ce post, je vais vous parler tout particulièrement d’un cas d’usage de la réplication logique : la migration majeure de PostgreSQL avec réduction du temps d’indisponibilité des données à (presque) 0.
Dans le monde des SGBD, il existe deux manières de faire de la réplication, la réplication physique, qui consiste à recréer un clone de l’instance primaire (avec donc des fichiers identiques au bit près) et la réplication logique où l’idée n’est plus de répliquer en bas niveau, mais de répliquer les données, leur stockage sur disque pouvant être différent.
La réplication physique est très appréciée pour la haute disponibilité ou assurer une diminution du risque de perte de données (réplication synchrone). Cependant, la réplication physique impose des contraintes qui peuvent poser problème :
Dans le cadre d’une migration de PostgreSQL, c’est la contrainte “même version de PostgreSQL” qui va nous poser problème.
Je vous conseille de lire cet article si vous souhaitez plus d’informations sur la réplication logique.
Imaginons que nous avons une première instance de PostgreSQL en production en version 10. Nous allons créer une deuxième instance PostgreSQL en version 11 à côté. Puis nous allons mettre en place la réplication entre la version 10 et la version 11 et quand toutes les données auront été recopiées, nous pourrons basculer les connexions de l’application sur la nouvelle instance.
Cette technique n’est intéressante que si une technique plus classique
(pg_upgrade ou pg_dump | psql ) n’est pas utilisable. Le cas classique où ces
techniques ne sont pas utilisables est la conjonction d’un changement de
machine, d’un gros volume et d’un besoin de limitation de l’indisponibilité du
service.
Autre précision importante : la réplication logique n’est possible que si une clé primaire a été définie sur chaque table à répliquer.
Mon instance est initialisée avec les données de l’excellent site pgexercises.com. Si vous ne le connaissez pas, c’est l’occasion de le découvrir!
Ce modèle a l’avantage d’être concis, mais il lui manque un type d’objet : les séquences. Comme celles-ci sont importantes (car elles ne sont pas encore répliquées dans la réplication logique native de PostgreSQL), j’ai modifié le modèle ainsi :
exercises=# select 'alter table bookings alter column bookid add generated always as identity (start with ' || max(bookid)+1 || ')' from bookings
union
select 'alter table facilities alter column facid add generated always as identity (start with ' || max(facid)+1 || ')' from facilities
union
select 'alter table members alter column memid add generated always as identity (start with ' || max(memid)+1 || ')' from members;
?column?
---------------------------------------------------------------------------------------------
alter table bookings alter column bookid add generated always as identity (start with 4044)
alter table members alter column memid add generated always as identity (start with 38)
alter table facilities alter column facid add generated always as identity (start with 9)
(3 rows)
exercises=# \gexec
ALTER TABLE
ALTER TABLE
ALTER TABLE
Voici les grandes étapes de cette migration :
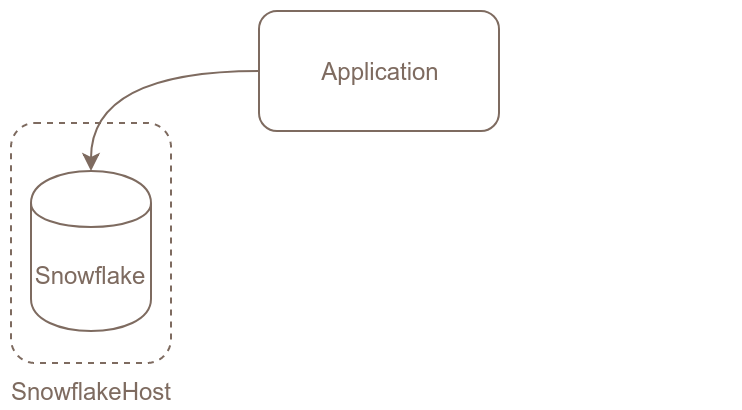
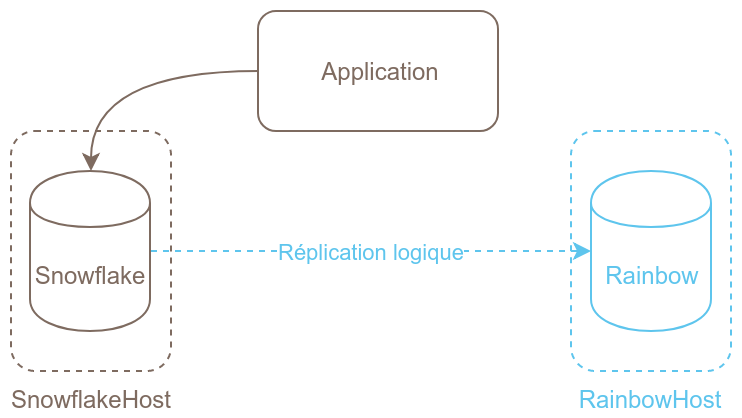
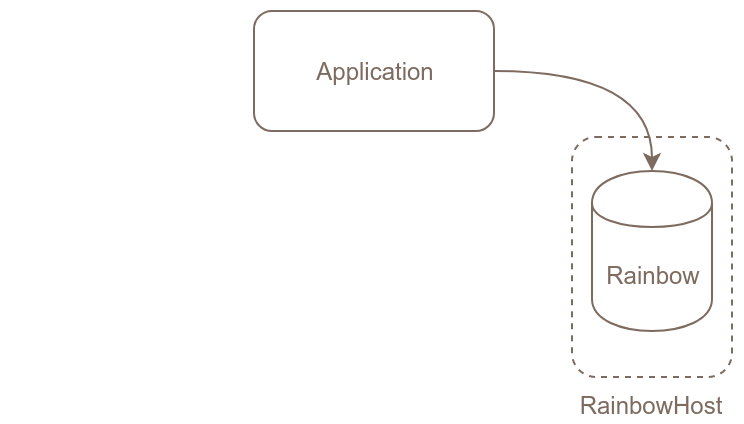
C’est l’étape qui devrait poser le plus de problème : si le paramètre
wal_level de votre instance n’est pas à logical, vous allez être obligés de
la redémarrer pour permettre cette modification, ce qui implique une
indisponibilité de la production de quelques secondes/minutes (suivant la
quantité de données à écrire pour le checkpoint).
L’opération en elle-même n’est pas très compliquée, il faut modifier le fichier
postgresql.conf (que vous trouverez normalement dans le répertoire du cluster ou
dans /etc/postgresql/version/nom_cluster sur une distribution Debian-based) et
redémarrer l’instance.
vi /etc/postgresql/10/snowflake/postgresql.conf
pg_ctlcluster 10 snowflake restart
Comme d’habitude, il est conseillé d’utiliser les dépôts PostgreSQL plutôt que ceux des distributions. De plus, il est fortement déconseillé d’utiliser son propre PostgreSQL compilé en production. Vous trouverez toutes les étapes, OS par OS sur cette page.
Pour mon Ubuntu, les commandes sont les suivantes (j’utilise la directive
create_main_cluster pour empêcher l’initialisation de mon cluster. Voir cet
article pour plus d’informations) :
sudo mkdir /etc/postgresql-common
sudo vi /etc/postgresql-common/createcluster.conf
sudo vi /etc/apt/sources.list.d/pgdg.list
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get install postgresql-11
Puis, je vais intialiser mon cluster, ce qui me permet de personnaliser tout ça (et j’en profite pour activer le checksum sur les pages, c’est toujours une bonne idée de le faire) :
sudo pg_createcluster 11 rainbow -- --data-checksums
Pour la configuration de votre nouveau cluster, le plus simple est de prendre le
fichier de configuration de votre nœud primaire et de le modifier pour l’adapter
(listen_addresses et/ou port et les chemins pour les différents répertoires
et pour l’archivage, notamment).
Pour éviter que l’application ne puisse se connecter à la nouvelle instance, il
est préférable de ne pas modifier le fichier pg_hba.conf pour l’instant.
Il est ensuite très simple de démarrer le nouveau cluster :
sudo pg_ctlcluster 11 rainbow start
Maintenant, mes deux instances PostgreSQL tournent :
@snowflakehost:~# sudo pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
10 snowflake 5432 online postgres /var/lib/postgresql/10/snowflake /var/log/postgresql/postgresql-10-snowflake.log
@rainbowhost:~# sudo pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
11 rainbow 5432 online postgres /var/lib/postgresql/11/rainbow /var/log/postgresql/postgresql-11-rainbow.log
J’ai une instance en version 10 qui s’appelle snowflake et une instance en version 11 qui s’appelle rainbow.
La réplication logique ne réplique pas le DDL (Data Definition Language), il faut donc initialiser la structure des bases de notre instance.
Attention: à partir de ce moment, il ne faut plus qu’il y ait de modification de schéma sur l’instance primaire, sous peine de casser la réplication logique.
@snowflakehost:~# sudo -u postgres pg_dumpall -s > /tmp/myschemas.sql
@snowflakehost:~# scp /tmp/myschemas.sql rainbowhost:/tmp/myschemas.sql
@rainbowhost:~# sudo -u postgres psql -f /tmp/myschemas.sql
Sur le serveur de production, il faut déclarer la publication en ajoutant pour
chaque base toutes les tables à répliquer. Dans mon cas, je n’ai qu’une base de
données à répliquer. La réplication logique fonctionnant par base, si vous avez
plusieurs bases à répliquer, il faudra jouer l’ordre create publication sur
toutes vos bases.
@snowflakehost:~# sudo -u postgres psql exercises
psql (10.6 (Ubuntu 10.6-1.pgdg18.04+1)
Type "help" for help.
exercises=# CREATE PUBLICATION p_upgrade FOR ALL TABLES;
CREATE PUBLICATION
Sur la nouvelle instance, il faut créer la souscription, ce qui permet de
mettre en place la réplication. De la même manière, il faudra jouer l’ordre
create subscription sur chaque base de votre instance si vous avez plusieurs
bases de données.
@rainbowhost:~# sudo -u postgres psql exercises
psql (11.0 (Ubuntu 11.0-1.pgdg18.04+2))
Type "help" for help.
exercises=# CREATE SUBSCRIPTION s_upgrade CONNECTION 'host=snowflakehost dbname=exercises' PUBLICATION p_upgrade;
NOTICE: created replication slot "s_upgrade" on publisher
CREATE SUBSCRIPTION
(Dans mon exemple, je fais une connexion sur le port par défaut sans le préciser.
Vous pouvez bien sûr préciser le port avec port=..., utiliser un autre user de connexion
avec user=... etc.)
Il n’y a plus qu’à attendre que la copie des données se fasse. Cela peut prendre un peu de temps en fonction de votre volume de données et de l’activité de votre instance primaire.
Vous saurez que tout est en ordre quand la requête suivante ne renverra plus de lignes :
select * from pg_subscription_rel where srsubstate <> 'r';
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+----------
(0 rows)
(r signifie ‘ready’, cela veut dire que l’initialisation des données est terminée et que l’instance récupère les modifications au fil de l’eau.)
Si vous utilisez des séquences, celles-ci ne sont pas mises à jour par la
réplication logique. Entre l’initialisation de votre nouvelle instance et la
bascule, le flux de production a donc continué d’incrémenter les valeurs des
séquences. Il faut donc les synchroniser pour éviter d’avoir des
erreurs de type duplicate key lors de l’insertion de données.
On va donc profiter de la bascule pour remettre à niveau les séquences.
La première chose à faire est de couper le flux de production en arrêtant
l’application et en modifiant pg_hba.conf sur le serveur de production.
@snowflakehost:~# sudo -u postgres psql exercises
exercises=# select 'select ''select setval(' || c.oid || ','' || last_value ||'');''
from "' || n.nspname || '"."' || c.relname || '"'
from pg_class c
inner join pg_namespace n
on c.relnamespace = n.oid
where c.relkind='S';
?column?
------------------------------------------------------------------------------------------
select 'select setval(16438,' || last_value ||');' from "cd"."bookings_bookid_seq"
select 'select setval(16440,' || last_value ||');' from "cd"."facilities_facid_seq"
select 'select setval(16442,' || last_value ||');' from "cd"."members_memid_seq"
(3 rows)
exercises=# \t
Tuples only is on.
exercises=# \o /tmp/mysequences.sql
exercises=# \gexec
Nous obtenons alors un fichier sql à jouer sur la nouvelle instance :
@rainbowhost:~# sudo -u postgres psql -f /tmp/mysequences.sql
Il faut modifier tout d’abord le pg_hba.conf de la nouvelle instance pour
permettre à vos applications de s’y connecter (ne pas oublier de modifier
listen_addresses dans postgresql.conf si vous ne l’aviez pas déjà fait) et vous pouvez ensuite basculer
le paramétrage de votre application pour qu’elle pointe sur la bonne instance.
Ça y est, la bascule est complète et tout fonctionne comme il faut. Il vous reste à supprimer les souscriptions :
DROP SUBSCRIPTION s_upgrade;
et à arrêter et droper l’ancien cluster :
sudo pg_ctlcluster 10 snowflake stop
sudo pg_dropcluster 10 snowflake
Une migration de PostgreSQL en minimisant le temps d’indisponibilité au maximum est possible. Cela demande un peu de préparation, mais je vous encourage vivement à pratiquer ce genre de choses pour ne pas avoir besoin de le découvrir dans l’urgence un jour.
Si vous êtes dans une version de PostgreSQL inférieure à la version 10, vous
pouvez utiliser soit l’extension pg_logical (PostgreSQL >= 9.4) ou Slony pour
une version inférieure à la 9.4. Si vous êtes dans ce cas, je vous encourage
vivement à migrer très rapidement pour, entre autres, rester sur une version
supportée.



LOXODATA
SÀRL au capital de 380 000 €
RCS Vesoul-Gray B 520 264 896
SIRET 520-264-896 00017
Code APE 6202A
N° TVA Intra Com. FR01520264896
Siège social: 31 rue Maurice Gillot, 70000 Navenne
Téléphone fixe: +33 1 797 2 5775
Directeur de la publication: Stéphane Schildknecht
Hébergeur :
OVH SAS
2 rue Kellermann
59100 Roubaix - France
RCS Lille Métropole 424 761 419 00045