Benchmarking pratique (partie 1)
 2017-09-25
2017-09-25
 1576 mots, 8 minutes de lecture
1576 mots, 8 minutes de lecture
 Emeric Tabakhoff
Emeric Tabakhoff
 2017-09-25
1576 mots, 8 minutes de lecture
Emeric Tabakhoff
2017-09-25
1576 mots, 8 minutes de lecture
Emeric Tabakhoff
Lors du PGDAY Paris de mars de cette année, j’ai pu assister à la conférence de Fabien Coelho sur le benchmarking que je vous ai retranscrite ici.
J’ai aussi eu la chance de voir Kaarel Mopel de Cybertec mentionner pgbench-tools que je me suis empressé de regarder.
pgbench-tools est un ensemble d’outils d’automatisation de tests de performance.
Il s’appuie sur pgbench, outil faisant partie des contributions de base installées lors d’une installation complète de PostgreSQL.
Les scripts benchwarmer et runset servent ensemble à envelopper pgbench et sérialiser les tests.
Il est également possible de collecter les statistiques, que ce soit au niveau de l’OS (utilisation mémoire, processeur, etc.) ou au niveau de PostgreSQL (buffers cache et checkpoints, notamment).
Enfin d’autres scripts interviennent pour la configuration de base des tests ou pour monitorer l’utilisation de la mémoire.
Si ce n’est pas déjà fait, je vous conseille de vous familiariser avec la documentation de pgbench et de prendre connaissance de mon précédent post sur “le benchmarking fait correctement”.
Pgbench-tools peut faire des tests automatisés : “scale”, clients, temps de test, le régime “Heure de pointe” et le régime “Normal”. Comme déjà couvert dans un précédent article, le bench ne s’effectue pas uniquement avec une simulation par pic d’activité.
Il convient également de régler le bench pour un régime dit “normal” (option SETRATES). C’est ici à vous de déterminer quel sera le nombre de transactions par seconde en moyenne sur votre instance.
git : avec un git clone, on peut copier le dépôt en local. Il est également possible de télécharger et décompresser l’archive.
GNUplot est utilisé pour la génération des graphiques pour les rapports. Il n’existe pas de substitut.
Tout d’abord, il faut commencer par créer les bases pour le bench et pour les résultats :
createdb results
createdb pgbench
Puis, initialiser la base de données avec le script d’initialisation :
psql -f init/resultdb.sql -d results
Pensez à déclarer la bonne base de données dans la requête ci-dessus, mais également dans le fichier config présent à la racine du dossier et prérempli avec des valeurs par défaut.
Enfin, créer le set initial qui va nous servir de référence :
./newset 'Initial Config'
Un set est un ensemble de tests. Pour une configuration donnée (de pgbench-tools et de l’instance), on lance l’outil de benchmark. Ceci permet de ranger les tests par catégorie.
Le mot Scale qui peut se traduire littéralement par échelle.
On y fait parfois référence avec le terme “scaling factor” (facteur d’échelle).
Il correspond à un coefficient multiplicateur sur la taille de la base de données pgbench.
Les transactions par seconde seront abrégées par tps.
La valeur appelée client est le nombre d’accès concurrents à l’instance créés par l’outil pour simuler le nombre de clients.
La latence est le temps que met le client à rendre la main après l’envoi de la transaction.
Le tripyptique avg_latency, max_latency, 90%< : respectivement latence moyenne, latence maximale et la valeur de latence du 9e décile. Ils décrivent la répartition de la latence.
Les scripts importants pour bien démarrer sont :
./newset donne la liste des sets qui ont été créés ;./newset 'nom_du_test' ajoute un nouveau set à la liste../runset lance la série de tests ;pgbench) ;results) ;sda)../webreport génère un rapport index.html avec des graphiques GNUplot. Il se lance automatiquement à la fin de la série de tests.Il comporte une partie vue générale :
Vous trouverez ci-dessous deux exemples de graphiques produits :
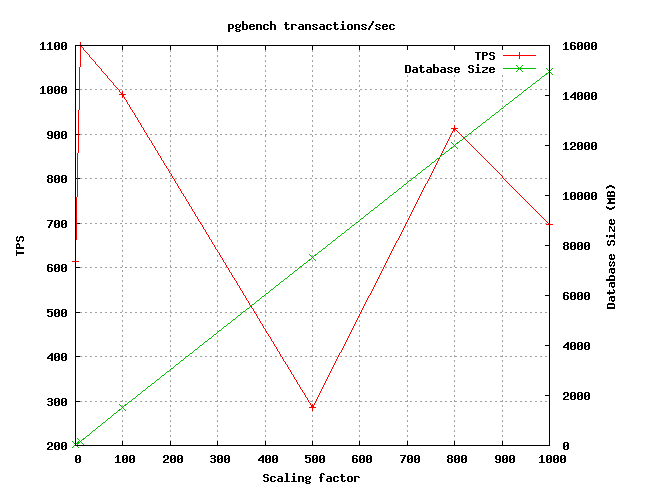
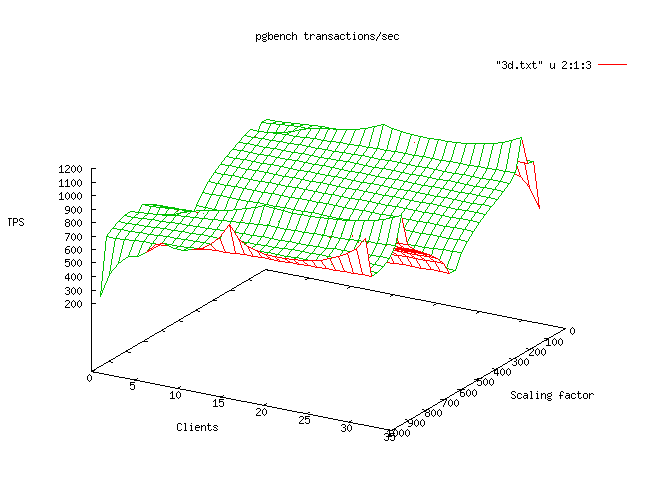
Ensuite pour chaque test, un résultat plus détaillé est produit comportant :
set, scale, tps, avg_latency, 90%\<, max_latency) ;set, scale, clients, rate_limit, tps, avg_latency, 90%\<, max_latency) ;set, test, scale, clients, rate_limit, tps, max_latency, chkpts, buf_check, buf_clean, buf_backend, buf_alloc, max_clean, backend_sync, max_dirty, wal_written, cleanup).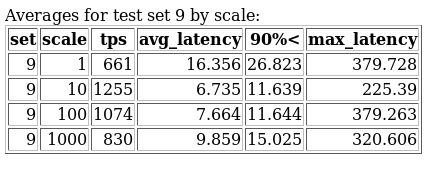
Il est important de coller à la réalité pour obtenir un résultat pratique.
Premièrement, je recommande vivement d’activer l’écriture dans les WAL (fsync) ainsi que la sauvegarde et l’archivage des WAL.
Ceci est d’autant plus important que les écritures ont lieu dans les WAL, dans la base, dans les clog et dans les logs.
Ces écritures ont un impact sur les performances lors du bench, désactiver l’écriture et l’archivage des WAL nuirait à la pertinence du résultat.
Au regard de ses informations, une fois le bench lancé, des WAL vont être produits, beaucoup de WAL, j’ai bien dit BEAUCOUP de WAL. Vous pouvez donc choisir de faire une purge manuelle ou de mettre un système de fichiers immense pour anticiper ce problème.
L’outil original tel qu’il est sur le git de son auteur c’est ici.
Pour ma part, je suis tombé sur des problèmes de compatibilité avec PostgreSQL 9.6. Il m’a donc été nécessaire de mettre à jour l’outil. Voici le lien à jour de juin 2017 pour cette version avec les modifications ad hoc.
En effet, dans la version 9.6, la génération de nombres aléatoires utilisée par les scripts pgbench change de format (cf. documentation). J’ai également intégré des modifications/améliorations dont je vous parlerai plus en détail dans le prochain article.
C’est un choix parfait pour faire une comparaison exhaustive du changement d’un paramètre : Vous souhaitez améliorer des performances de façon générale dans le cadre d’une utilisation particulière de votre instance de base de données. Seules quelques heures de test sont nécessaires. Il n’est alors pas nécessaire d’entrer plusieurs échelles : seule la vôtre convient.
Votre configuration matérielle change : Vous gagnez au loto et vous investissez dans votre matériel, ou au contraire les choix stratégiques vous imposent de virtualiser ou de diminuer le nombre de noeuds de votre infrastructure. Vous souhaitez donc connaître la façon dont sera impactée votre instance avec ce nouveau matériel. Une série de comparaisons avec les 2 configurations permettra de se rendre facilement compte de l’évolution.
Il s’inscrit parfaitement dans le cas de ce que l’on pourrait appeler le “bench continu”. (Vous êtes riche comme Bruce Wayne : du temps, de l’argent et évidemment un Bat-Computer). Un serveur identique à la production sur lequel on répète des tests de bench en changeant des variables PostgreSQL. Dans ce scénario, difficile à proposer dans un contexte de restriction financière, on peut même imaginer un petit cluster avec un rejeu des transactions de production grâce à un proxy ou à un fichier de log. Nous reviendrons sur cette solution (passionnante à mon sens) dans un prochain article.
Comme on peut le constater à la lecture de cet article, pgbench-tools est un outil exhaustif qui permet d’industrialiser et fiabiliser ses tests de performance, tout en générant un rapport complet.
Beaucoup d’aspects comme la reproductibilité, la sérialisation et les statistiques sont d’ores et déjà un bond en avant en comparaison de pgbench seul.
La compatibilité avec la version 9.6 étant un énorme frein, la correction me paraissait d’autant plus urgente avec la version 10 de PostgreSQL qui arrive à la fin de l’année. J’ai poussé cette modification, mais celle-ci reste en attente de validation par l’auteur Greg Smith. Je ne doute pas de la nécessité de devoir apporter d’autres corrections pour la nouvelle version qui s’annonce.
Trouvant un grand intérêt à cet utilitaire, j’ai décidé de le forker et d’y amener d’autres améliorations et corrections. Je remets ici le lien : pgbench-tools avec les modifications si vous l’avez manqué plus haut.
Nous avons vu les possibilités théoriques de l’outil, dans le prochain volet, je vous parlerai de certaines fonctionnalités avancées avec des exemples pour démarrer un bench.
A vos benchs !



LOXODATA
SÀRL au capital de 380 000 €
RCS Vesoul-Gray B 520 264 896
SIRET 520-264-896 00017
Code APE 6202A
N° TVA Intra Com. FR01520264896
Siège social: 31 rue Maurice Gillot, 70000 Navenne
Téléphone fixe: +33 1 797 2 5775
Directeur de la publication: Stéphane Schildknecht
Hébergeur :
OVH SAS
2 rue Kellermann
59100 Roubaix - France
RCS Lille Métropole 424 761 419 00045